Improve your code’s maintainability by dropping unit tests

The way you test has a huge impact on your codebase maintainability.
In this article I’ll try to convince you that by zoning out and seeing the broader picture you can deeply improve it.
Let's start with why:
Why do we test?
Nobody tests for the sake of it, everybody has something in mind that is trying to achieve by testing, and most of us are trying to achieve the same things:
- Tests as a safety net — The primary objective of tests is to give you confidence that your code works as expected. They are there to spot bugs before they reach your users.
- Tests as documentation & specification — Tests should explain and specify the behaviour of your code. You have an objective while testing, and normally that objective is the whole point of the code itself, so the clearer and the more specified your tests are, the better.
- Tests as bug locators — If you’re Sherlock Holmes, your tests are John Watson, if some feature was murdered, you want to find the responsible, and fast. Your tests will (hopefully) pinpoint the murder scene, so you can start analysing and clearing the mess up. The better and more atomically they pinpoint, the faster you can get to the bottom of the case.

There is much more to be said around these “whys” of testing, so I highly recommend that you give a read to this article if you’re interested:
Maximizing confidence
We can agree that the first and foremost goal of testing is giving you the confidence to ship well-prepared code for your users, as stated above. We want to spot every problem before our users do.
We want to make sure that when our application is failing, our tests are failing, and when our application is working, our tests are working. This is our leading principle.
But how can we maximize this confidence?
Testing behaviour
We can achieve this by testing exactly how we want it to behave. We can see emerging practices like TDD and BDD, all intended to maximize behaviour oriented software.
“The more your tests resemble the way your software is used, the more confidence they can give you.” — Kent C. Dodds
But how can we be sure that our app is testing solely the behaviour, and it is not tied with the way we are achieving that behaviour?

Refactoring rule
“Refactoring is a disciplined technique for restructuring an existing body of code, altering its internal structure without changing its external behaviour.” — Martin Fowler
So if we’re only interested in testing behaviour, it logically comes that refactoring shouldn’t make tests fail.
This is the refactoring rule. When you refactor your code, your tests should still be passing. All of them.
This is a huge maintainability improvement. After all, most apps follow a feature increase when in development, and its maintenance mode is most about exchanging certain parts and making sure it all still works as expected. If you are free to refactor your code without the fear of having to do a huge test clean up afterwards, you will be much more motivated to do so.
But how can we achieve this? How can we test behaviour, without clouding our tests with the specifics?
Guidelines
If it’s private, don’t test it
Don’t forget, you want to test the behaviour of a module, in other words, how it responds to the external world. You are interested in the outputs of that module, given some specific inputs. Whatever the module uses to generate those inputs you don’t care, as long as the behaviour is there. Private methods (normally helpers) are exactly that, private details that you don’t wanna test.
But don’t take it for me, take it from Kent:
Try TDD
TDD forces you to test before you have the implementation, so you have no biases. You will be forced to be thinking about the behaviour that you want to test, because that’s the only thing you know beforehand, really.
Remember, your tests aren’t meant to be a secondary implementation.
Properly name your tests
Naming your tests correctly is the most cost-effective advice I can give you. The test name is your guide when you’re building the test, so if you keep its implementation and technical details agnostic, it will be much easier to understand its behaviour when either you or your colleagues revisit that test.
There’s always at least two people programming: You and you in two months.
If you name it properly, in a behaviour-driven manner, it will help them pinpoint exactly where the behaviour that they want to change, because of some new feature or bug, thus improving maintainability.
📝 I prefer the SHOULD … WHEN pattern over the classical GIVEN -> WHEN -> THEN and the reason is simple. Engineers are people in a hurry and explaining the “then” first usually saves a bit of time. Pretty much like a TL;DR.

Mocking only data sources
When you’re mocking, you are basically saying that you know that a certain part of your application will work in a certain manner. You are fixing a part of your code on your application, not allowing it to be flexible, thus more hardly maintainable.
Normally, the only fixed parts in your application are your data sources. If you are testing a handler, you know that it is getting data from a gateway, so that’s the only thing you mock (Arguably, you could even say that your data is coming from a database, thus only mocking the database itself. But as long as you are following the dependency inversion principle you should be ok mocking that gateway).
If you’re testing a Gateway, you know that it gets data from an external server, so you mock that server.
If you mock the internals of your application just because they are separated, you are doing it wrong and will end up tying your tests with your implementation, breaking the refactor rule and therefore severely hurting your codebase maintainability.
Consider the following example:
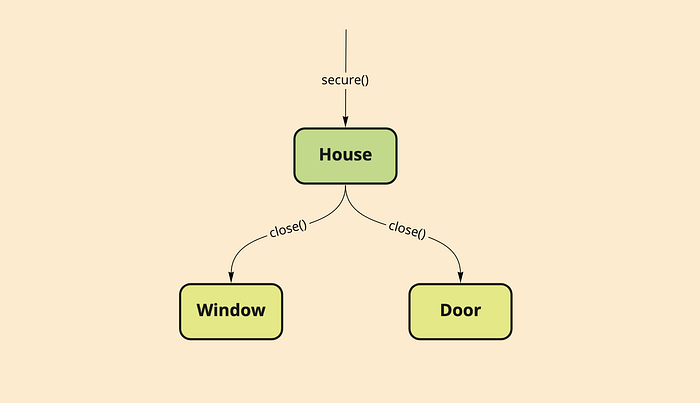
Here we have a module (House) and two sub-modules (Window & Door).
Let’s pretend we want to test the following use case: Securing our house so no one breaks in. How should we test this?
We might be tempted to call the secure method, and then verifying that our window and door were closed. For this, we would mock Window and Door and assert on its close method calls.
This is just plain wrong since we are basically duplicating our implementation.
Assume for a second that I add a second window and call its close method within my secure() call. Now I’m in a state where my application works, but my tests don’t, breaking our motto.
What if I add a garage and forget to call its close() method on the secure() of my house? Now my tests are passing and my application is not working. Red flags all over.
The behaviour that we want to test is simply verifying that we can’t break into the house after we secure it, so the way to test it would be to secure it, and then assert that we fail to break in (probably through some breakIn() method).
⚠️ Well but now our House tests are dependent on the Window and Door implementation! This is like an integration test!
Exactly my point.
A new testing approach
Software development has evolved and with so the methodologies around it. We witnessed the growing popularity of Agile, with fast iteration cycles and CI/CD. But with that, the maintainability stakes are higher than ever. Maintainability is not just something that it’s good to have, it’s a top priority.
Traditional isolated (unit) tests tend to over-mock your codebase, tightening your implementation to your tests, thus harshly reducing maintainability. They have to end.
“Write tests. Not too many. Mostly integration.” — Guillermo Rauch
You want to maximize behaviour testing, and that behaviour cascades down to the module dependencies (this makes sense since it obviously needs them to work properly)
📝 If you want, you can think of your new unit tests as integration tests on components or classes with no dependencies. In the example above this would be window & door if they had no dependencies.
Not all is roses
Everything in this world is about pros outweighing the cons, and this new approach is no exception, so naturally, it has some cons.
When all of your tests are connected, you will greatly worsen the Bug locator capabilities of your tests.
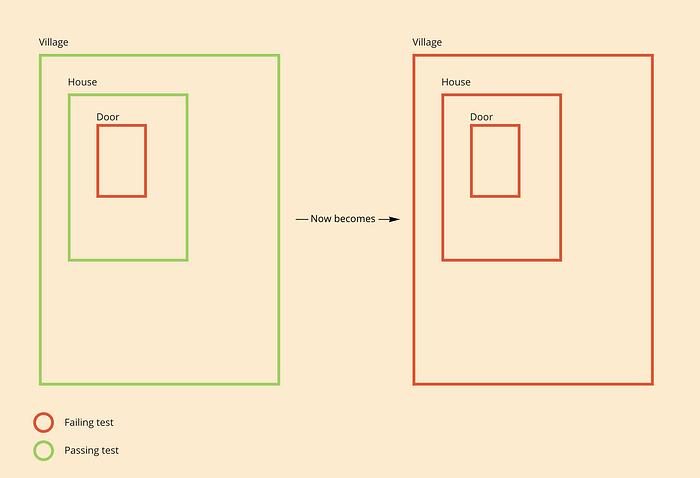
If your tests are intertwined, you will end up seeing your innermost layers propagating their bugs towards the outer layers. These would be still pretty straightforward to streamline and identify, but definitely not as much as they could be. There are ways to minimize this effect, but I’ll elaborate on that in a future article.
Conclusion
Stop thinking about unit tests as a test for an isolated part of your code, it doesn’t need to be.
There are a million ways to test, all of its with its pros & cons. If you think your codebase could improve its maintainability and find yourself spending too much time correcting tests, I highly recommend you give this a try.
I’d be more than happy to learn about your personal experiences, and understand what worked for your team, and what didn’t.
And thank you if you made it this far!
Happy testing!

